转载自知乎 **一句话结论:现代大容量硬盘组成的RAID 5单盘故障后,重建失败的概率相当高,不可忽略;但数据本身还是基本安全的(会丢失部分文件),只是可能需要一个比较麻烦的恢复方案。** 楼上包括高赞回答在内一堆说两个硬盘同时坏的,要加一个热备盘的,都是没**仔细**看过问题里面的链接就回答的。在回答问题的现在,这个链接失效了,但网上还是有人转载过的,例如这篇[1]: > **DBA亲,你们的RAID5阵列有保障吗?** > marbury关注0人评论10546人阅读2014-02-21 10:30:24 > 该文章主要整理论坛内容。(论坛地址:[http://bbs.et8.net/bbs/showthread.php?t=1026112)](https://link.zhihu.com/?target=http%3A//bbs.et8.net/bbs/showthread.php%3Ft%3D1026112%EF%BC%89) > > 很多人遇到过服务器RAID5挂掉,往往掉一个盘后,第二个盘也立刻挂掉。 > > 引用:RAID 5也是以数据的校验位来保证数据的安全,但它不是以单独硬盘来存放数据的校验位,而是将数据段的校验位交互存放于各个硬盘上。这样,任何一个硬盘损坏,都可以根据其它硬盘上的校验位来重建损坏的数据。硬盘的利用率为n-1。如果挂掉两个盘,数据就玩完了。 > 理论上两个硬盘同时失效的概率是很低的,但为什么会这样呢? > 引用:从数学角度说,每个磁盘的平均无故障时间 (MTBF) 大约为 50 万至 150 万小时(也就是每 50~150 年发生一次硬盘损坏)。实际往往不能达到这种理想的情况,在大多数散热和机械条件下,都会造成硬盘正常工作的时间大幅减少。考虑到每个磁盘的寿命不同,阵列中的任何磁盘都可能出现问题,从统计学角度说,阵列中 N 个磁盘发生故障的机率比单个磁盘发生故障的机率要大 N 倍。结合上述因素,如果阵列中的磁盘数量合理,且这些磁盘的平均无故障时间 (MTBF) 较短,那么在磁盘阵列的预期使用寿命过程中,就很有可能发生磁盘故障(比方说每几个月或每隔几年就会发生一次故障)。 > 两块磁盘同时损坏的几率有多大呢(“同时”就是指一块磁盘尚未完全修复时另一块磁盘也坏掉了)?如果说 RAID 5 阵列的MTBF相当于MTBF^2,那么这种几率为每隔10^15个小时发生一次(也就是1万多年才出现一次),因此不管工作条件如何,发生这种情况的概率是极低的。从数学理论角度来说,是有这种概率,但在现实情况中我们并不用考虑这一问题。不过有时却是会发生两块磁盘同时损坏的情况,我们不能完全忽略这种可能性,实际两块磁盘同时损坏的原因与MTBF基本没有任何关系。 > 对这种情况来说,这里首先要引入一个一般人不常接触到的概念:BER 硬盘误码率,英文是BER(Bit Error Rate),是描述硬盘性能的一个非常重要的参数,是衡量硬盘出错可靠性的一个参数。这个参数代表你写入硬盘的数据,在读取时遇到不可修复的读错误的概率。从统计角度来说也比较少见,一般来说是指读取多少位后会出现一次读取错误。 > 随着硬盘容量增加,驱动器读取数据的误读率就会增加,而硬盘容量暴涨,误码率的比例一直保持相对增加。一个1TB的驱动器是需要更多读取整个驱动器,这是在RAID重建期间发生错误的概率会比300G 驱动器遇到错误的几率大。 > 那这个错误的几率到底有多大呢?或者说,我们写入多少GB数据,才会遇到1byte的读取错误呢?看这篇文章: > [http://lenciel.cn/docs/scsi-sata-reliability/](https://link.zhihu.com/?target=http%3A//lenciel.cn/docs/scsi-sata-reliability/) > > 对于不同类型的硬盘(以前企业级、服务器、数据中心级硬盘用SCSI/光纤,商用、民用级别是IDE;现在对应的则是SAS/SATA; > 他们的MRBF(平均无故障时间)是接近的,但是BER便宜的SATA硬盘要比昂贵的SCSI硬盘的误码率(BER)要高得多。 > 也就是说,出现某个sector无法读取的情况,SATA要比SCSI严重得多。具体区别在固件上:遇到读取不过去,或者写入不过去的坏道时,家用硬盘会花费1分钟以上的时间去尝试纠正错误,纠正不了就直接用备用扇区代替,这个时间超过阵列控制器能容忍的限度,所以遇到这种情况直接掉盘;企业级的磁盘会把这项工作放在后台进行,不需要停顿1分钟左右的时间,从而不影响阵列运行。在BER 硬盘误码率上没有任何区别。 > 按照文中的计算,一个1TB的硬盘,通常你无法读取所有sector的概率达到了56%,因此你用便宜的大容量SATA盘,在出现硬盘故障的情况下重建RAID的希望是:无法实现。 > 用1TB的SATA硬盘做RAID5的话,当你遇到一个硬盘失效的情况,几乎剩下的两个以上硬盘(RAID5最少组合是3个)铁定会遇到一个硬盘读取错误,从而重建失败。 > 所以,以前小硬盘做RAID5,基本很少遇到同时挂掉两个盘的情况;现在硬盘大了,出问题的概率也越来越大了。 > 对于跑RAID的用户,对整个硬盘进行读取的事情经常发生。即使系统足够和谐,知道不对你报告那些出现在你从不读取的文件中的坏道,但是也只是略过了报告这一步:它还是会找到所有的坏道,56%就来了。还有所谓的监控专用企业级SATA,其原理就是在固件上做手脚,让硬盘即使遇到写入的数据读取错误,也不管三七二十一直接跳过,不再重试读取(标准硬盘的读取方式是遇到某个扇区CRC错误自动重新再去读,直到读到正确的数据为止)。这对监控数据来说是理所当然的(大多数监控的硬盘都是在不停地写入,但是很少需要读取),除非遇到出现问题需要重现影像时。 > 现有的Raid5阵列的磁盘中有未检测到的错误的话,Hot Spare没办法解决。Hot Spare只能在某个磁盘下线的时候,及时的替换下线的盘进行Raid重建,如果其他磁盘有错误的话,重建还是会可能失败。 > 解决方法还是要在阵列健康状态下,进行定期或者其他方式的错误检查。一般的硬件阵列卡,也就是插在主板PCI/PCIX/PCIE/或者主板集成的RAID5,压根就没数据巡检(scrub)功能。企业级的数据存储,也只有到盘阵级别(比如IBM DS3000/4000/5000,DELL MD3000....etc)才有这类功能,但是你也看不到检查的结果,最多能在日志里看到某个硬盘CRC失败,然后跳红灯掉出来,阵列柜告警通知你换硬盘。你别想知道这个硬盘到底是彻底挂了呢,还是有读取错误,还是有坏道。。。总之两眼一抹黑。(ZFS上的RAIDZ有数据巡检(scrub)功能) > 总结遇到RAID5一次挂掉俩盘的概率 > 1、使用越大容量的硬盘做RAID5,遇到BER 扇区的概率越大;比如用100G硬盘做RAID5就比用1TB的安全; > 2、使用越多盘数的硬盘做RAID5,遇到BER 扇区的概率越大;比如用3个盘做的RAID5,比6个盘做的RAID5安全; > 3、使用越便宜的硬盘做RAID5,遇到BER 扇区的概率越大;比如用SCSI/FC/SAS盘比用IDE/SATA的RAID5安全; > 4、RAID5里面存放的数据越多,塞得越满,遇到BER 扇区的概率越大;比如存了100G数据的比存了1TB数据的RAID5安全;(REBUID时只读取存过数据的扇区,某些卡则不管三七二十一要读完整个盘) > RAID1/RAID10参与重建的只有一个盘,与raid5所有盘都需要参与重建相比,故障概率降低;RAID1 某一组磁盘故障,也不需要强制上线的操作,因为数据仍然存在,不需要组RAID也能读取,哪怕是换到其他没有raid卡的机器上数据仍能读出;而RAID5如果不能强制第二个掉下的硬盘上线,你一点东西都读不到。 > 对于DB来说:做raid 1+0 是最好不过啦!(备份时必不可少的;当RAID处理降级状态时,如重要数据容量不大,建议先做备份,当然这种备份应该是异机的,不可备份至当前已降级的RAID中。如果在REBUILD当中出现另外硬盘离线的情况导致RAID卷OFFLINE,切不可重建RAID,如确定后离线的硬盘,可通过强制上线恢复数据(有些控制器没有选项,就没办法了) > > > 本文出自 “技术成就梦想” 博客,请务必保留此出处[http://weipengfei.blog.51cto.com/1511707/1006565](https://link.zhihu.com/?target=http%3A//weipengfei.blog.51cto.com/1511707/1006565) 这篇文章有两个我认为不正确的地方: - 用硬盘厂家标称的MTBF来计算第二块硬盘发生故障概率是不适当的。如果参考谷歌的论文[2],5年内硬盘的最高年平均故障率为8.6%(下面估算中用稍高一点的10%进行估算)。按照这篇文章所说的1TB硬盘,假设平均写入速度为100MB/s计算,重建RAID 5需要写满一个硬盘,大概需要 ![[公式]](https://www.zhihu.com/equation?tex=1e12+%5Cdiv+100e6+%5Cdiv+3600+%3D+2.78) 小时。如果以8盘RAID5计算的话,单个硬盘故障后还有7个硬盘,在2.78小时内单个硬盘发生故障的概率可以用 ![[公式]](https://www.zhihu.com/equation?tex=10+%5C%25+%5Cdiv+365+%5Cdiv+24+%5Ctimes+2.78+%3D+3.17e-5) 计算。7个硬盘在2.78小时一个或一个以上硬盘出现故障的概率可以用binomial distribution(二项分布)的概率质量公式计算: ![[公式]](https://www.zhihu.com/equation?tex=Pr%5Cleft%28+X+%5Cgeq+1+%5Cright%29+%3D+%5Csum_%7Bi%3D1%7D%5E%7B7%7D%7B+%5Cbinom%7B7%7D%7Bi%7D+p%5E%7B7%7D+%5Cleft%281-p%5Cright%29%5E%7B7-i%7D%7D) ,其中P=3.17e-5。这里的这个公式可以简化为 ![[公式]](https://www.zhihu.com/equation?tex=1-Pr%280%29%3D1-%5Cbinom%7B7%7D%7B0%7Dp%5E%7B0%7D%281-p%29%7B7%7D) 后用Excel计算,计算函数为=1-BINOMDIST(0,7,3.17e-5,TRUE),计算结果为2.22e-4,也就是0.022%。如果考虑到RAID 5重建过程中还有其它IO应用,或者RAID卡重建性能较差,导致重建速度降低,假设平均写入速度只有20MB/s,则重建时间约为14小时,重建过程中出现第二个硬盘故障的概率为0.11%。也就是大概每1000次重建可能出现1次第二个硬盘故障。也就是说,在一个部署了上万硬盘并且均组成RAID5阵列的数据中心中,几乎每年都会发生一例,并非是文中所说的“在现实情况中我们并不用考虑这一问题”。2019年的今天,单个硬盘最大容量已经达到14TB,假设重建速度保持在20MB/s,这个概率会进一步提升到1.54%;即使重建速度提升到50MB/s,这个概率还有0.62%,超过1/200。**不过即使这样,和因为URE导致的重建失败的概率(见后文)相比,这也是一个相当低的概率。** 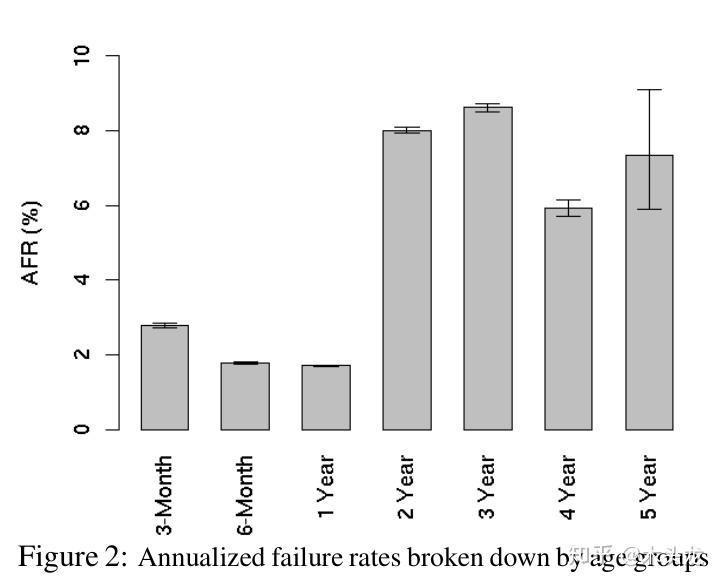 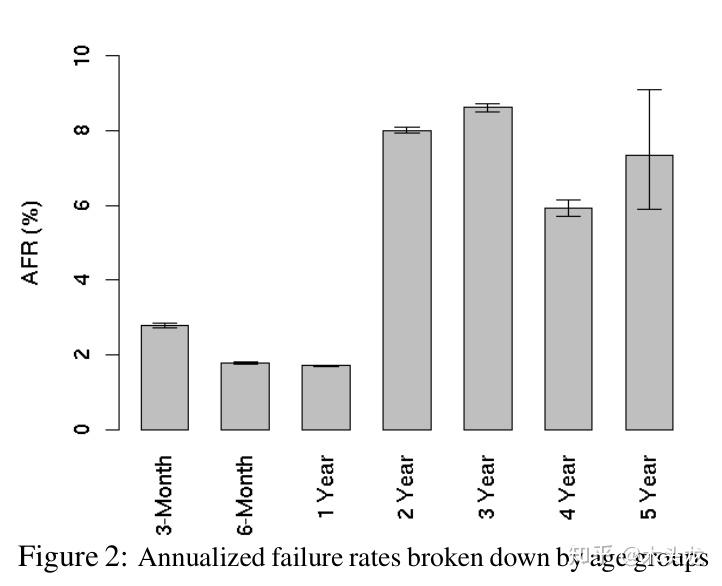 - “一个1TB的硬盘,通常你无法读取所有sector的概率达到了56%”这句话是不正确的,要搞清楚这个概率的出处,需要去看文中链接的文章。不过,这篇文章中引用的链接地址无法访问的,估计是博主换了域名,通过搜索找到新域名链接[3],但[3]依然没有给出这个数据是如何计算出来的。只提到: > 最近看到**[一篇文章](https://link.zhihu.com/?target=http%3A//permabit.wordpress.com/2008/08/20/are-fibre-channel-and-scsi-drives-more-reliable/)**讨论SATA和SCSI硬盘的可靠性问题。这篇文章的结论是:两种硬盘的故障率(**[MTBF](https://link.zhihu.com/?target=http%3A//en.wikipedia.org/wiki/MTBF)**)是极其接近的,只不过便宜的SATA硬盘要比昂贵的SCSI硬盘的**误码率([BER](https://link.zhihu.com/?target=http%3A//en.wikipedia.org/wiki/Bit_error_ratio))要高得多。**也就是说,出现某个sector无法读取的情况,SATA要比SCSI严重得多。按照他的计算,一个1TB的硬盘,通常你无法读取所有sector的概率达到了56%,因此你在出现硬盘故障的情况下重建RAID的希望是:**无法实现**。 点击上面的“这篇文章”的链接[4],原文部分摘录如下: > Where there is a difference between models, though, is with our old friend, the [bit error rate](https://link.zhihu.com/?target=https%3A//permabit.wordpress.com/2008/08/15/multiple-drive-failures-raid-6-vs-rain-ec/). The bit error rate is the rate at which a block just can’t be read from the disk, due to not being able to recover data from the [PRML](https://link.zhihu.com/?target=http%3A//en.wikipedia.org/wiki/PRML) and ECC codes on the platter. The whole drive doesn’t fail, but you can’t read that block. In a RAID system, this triggers reconstruction of that block from the remaining drives. > > As I describe in the video [“The Trouble with RAID”](https://link.zhihu.com/?target=http%3A//www.permabit.com/videos/raid45/permabit-raid45.asp), this bit error rate is the biggest problem with RAID technology today. In the event of a drive failure in a RAID 4 or RAID 5 set, every remaining drive must be read perfectly from start to finish or else data will be lost. With a 7+1 set of terabyte drives, this means 7 TB must be read. A bit error rate of 1 in 10^14 means that there’s a **44%** chance that can’t be done. 摘录部分翻译如下: 然而,不同型号(译注:原文指消费级硬盘及SCSI/光纤通道硬盘)之间存在的差异是我们所熟知的误码率。误码率是指由于无法通过PRML和ECC从盘片上的恢复数据而无法从磁盘读取某个扇区数据的概率。硬盘整体来说并未发生故障,但用户无法读取该扇区的数据。在RAID系统中,这会触发用其它硬盘上的数据对该扇区数据恢复的重建过程。 正如我在视频中描述的“RAID的麻烦”一样,这种误码率是当今RAID技术最大的问题。如果RAID 4或RAID 5中的驱动器发生故障,则剩余的每个硬盘都必须从头到尾“完美”的读取一遍,否则将会导致数据丢失。使用7+1个1 TB容量硬盘,这意味着必须读取7 TB。1/10^14的误码率为意味着有44%的概率无法做到(“完美”读取7TB数据)。 译注: - PRML:Partial-response maximum-likelihood,部分响应最大似然,一种提高磁头读取磁盘后产生的微弱模拟信号数字化准确度的技术。 - ECC:Error Correct Code,纠错码,一种通过传输/保存冗余编码的数据位,在原始数据发生传输错误时可以检测到错误并恢复出正确数据的技术。 [4]所提到的bit error rate,现在各家硬盘厂商的Datasheet中通常叫Non-recoverable Read Error rate,网上包括维基通常用Unrecoverable Read Error rate(URE,本文均使用此缩写),也就是[1]所提到的“**写入硬盘的数据,在读取时遇到不可修复的读错误的概率**”。 稍微解释一下,这个读错误产生的原因可能在于: - 数据写入硬盘时,数字信号转换为盘片上的模拟磁场信号过程中发生错误; - 数据存放过程中,因为外界的电磁干扰/宇宙射线/写入周围单元时磁头位置偏离导致的磁单元中部分磁性材料极性翻转; - 读取数据时,磁场信号转换为数字信号过程中发生错误; 在硬盘内部,这种错误其实是经常发生的,但一般来说每个扇区可能也就1~3 bit的数据发生这种错误。因此机械硬盘每个扇区后面有若干位ECC纠错码(早期的512B扇区硬盘是每扇区50Byte,现在的4K扇区硬盘是每扇区100Byte[5]),可以用于纠正此类错误。然而ECC不是万能的,如果读取某个扇区的数据时发生错误的位过多,ECC也无能为力,这个时候就发生“不可恢复的读取错误(也就是前面定义中的Unrecoverable Read Error)”了。按照硬盘厂家提供的参数,发生这种情况的概率——也就是URE,消费级硬盘一般是1e-14,企业级硬盘发生URE的概率一般是1e-15。 [4]并没有给出具体的计算根据URE计算RAID5重建成功概率的公式,这里稍微补充一下。如果某款硬盘的URE是1e-14/bit(这个可以从各家硬盘厂商的DataSheet中查到),并不代表每读取1e+14 bit就一定出现一次URE。同样可以用二项分布公式计算,读取1e14bit发生URE的概率: - 0次: ![[公式]](https://www.zhihu.com/equation?tex=Pr%5Cleft%28+X+%3D+0+%5Cright%29+%3D+%5Cbinom%7B1e14%7D%7B0%7D+%5Cleft%28+1e-14+%5Cright%29%5E%7B0%7D+%5Cleft%281+-+1e-14%5Cright%29%5E%7B1e14%7D%3D36.79+%5C%25) - 1次: ![[公式]](https://www.zhihu.com/equation?tex=Pr%5Cleft%28+X+%3D+1+%5Cright%29+%3D+%5Cbinom%7B1e14%7D%7B1%7D+%5Cleft%28+1e-14+%5Cright%29%5E%7B1%7D+%5Cleft%281+-+1e-14%5Cright%29%5E%7B1e14-1%7D%3D29.05+%5C%25) - 2次: ![[公式]](https://www.zhihu.com/equation?tex=Pr%5Cleft%28+X+%3D+2+%5Cright%29+%3D+%5Cbinom%7B1e14%7D%7B2%7D+%5Cleft%28+1e-14+%5Cright%29%5E%7B2%7D+%5Cleft%281+-+1e-14%5Cright%29%5E%7B1e14-2%7D%3D22.94+%5C%25) - …… 不过1e14次试验,1e-14的概率这样的数字,Excel是算不了了,可以用Python的scipy库计算: ```python >>> from scipy.stats import binom >>> binom.pmf(0, 1e14, 1e-14) 0.36787944117144045 >>> binom.pmf(1, 1e14, 1e-14) 0.2904884966524753 >>> binom.pmf(2, 1e14, 1e-14) 0.22937831594696387 >>> binom.pmf(3, 1e14, 1e-14) 0.04041420666321343 >>> binom.pmf(4, 1e14, 1e-14) ``` 我们只关心不发生URE的概率,也就是0次。因此二项分布的概率质量函数可以这样简化: ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Bequation%7D+%5Cbegin%7Baligned%7D+Pr%28X%3D0%29%26%3D%5Cbinom%7Bn%7D%7Bk%3D0%7Dp%5E%7Bk%7D%281-p%29%7Bn-k%7D%5C%5C+%26%3D%5Cfrac%7Bn%21%7D%7B0%21%28n-0%29%21%7Dp%5E%7B0%7D%281-p%29%5E%7Bn%7D%5C%5C+%26%3D%281-p%29%5E%7Bn%7D+%5Cend%7Baligned%7D+%5Cend%7Bequation%7D+) 而4个1TB硬盘组成的RAID 5,单盘故障后的重建过程需要读取的数据量为1e12 Byte×8 bit/Byte×(4-1)=24Tbit,而读取24Tbit过程中没有发生URE的概率则是(1-1e14)^24e12=78.68%。用Excel可以很轻松计算出重建RAID5过程中,不同误码率,不同容量的硬盘,组成4/8盘RAID 5的重建成功/失败概率,见下表(PS:Excel用简化公式计算和用scipy直接计算的结果会稍有出入,但可以忽略)。 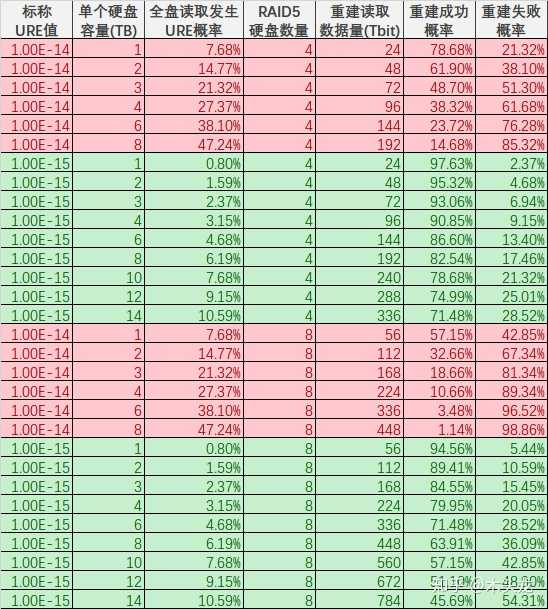 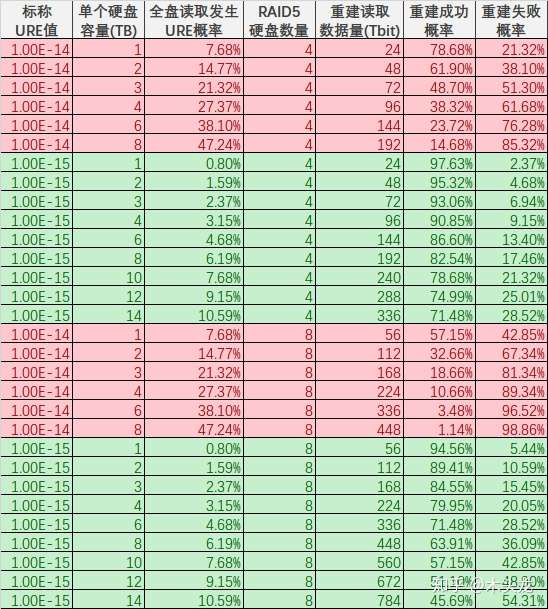 表中8个URE为1e-14建立的RAID 5重建成功概率为57.15%,和[4]所说的44%失败比较接近了。所以前面[1]所说的56%,是8个1TB硬盘组成的RAID5,重建过程中因为发生URE导致重建失败的概率。而单个1TB硬盘完全读取,发生URE的概率应该是7.68%。 进一步观察估算结果,其实单个硬盘全盘读取,8TB容量出现URE概率已经接近50%了。也所以现在8TB以上(含8TB)的硬盘,即使是消费级的,也都是1e-15的URE——起码希捷的最新产品线是这样。倒是企业级的Exos 5E8只有一款8TB型号,反倒标称的URE参数是1e-14。 从上表可见4个URE为1e-14的1TB硬盘组成的RAID 5重建失败的概率为21.32%,其实已经相当高了;8个URE为1e-14的硬盘组RAID5的话,1~2TB还可以拼一下脸,3~4TB那叫玩命,6~8TB就是碟中谍了。 需要说明的是,通常RAID 5是在硬件层面(有独立主控芯片的RAID卡,常说的硬RAID)或者块设备驱动层面(主板或操作系统,软RAID)实现的,与文件系统独立。因此RAID控制芯片或者驱动是无法知道RAID上某一段数据,到底是存有数据的文件,还是某个已经被删除的文件;也不知道某一段全0的数据,到底是未使用空间还是某个预分配磁盘空间但未使用的数据库文件。因此即使一个1TB*8,可用空间7TB的RAID 5,假设用户仅仅存放了50GB数据,重建的时候还是必须把7TB的数据全部读取一遍的。对于这种情况,RAID 5EE、RAID 2.0,以及由文件系统本身实现类似RAID 5的RAID Z1(ZFS文件系统),则是可以仅重建已经使用的50GB数据。 对比前面分析,重建过程中第二块硬盘出现故障导致重建失败的概率,8个1TB硬盘低速重建也不过0.11%,但因为URE导致重建失败的概率则是高达42.85%。题目和其它部分答案所提到的热备盘,其意义在于RAID卡/驱动发现单个硬盘故障的时候,可以马上进入重建过程。假设没有热备盘,需要24小时后才能开始重建,按照前面的计算,8个1TB硬盘组成的RAID 5的重建时间从14小时延长到38小时,这个期间第二块硬盘发生故障的概率约为0.30%,和发生URE导致重建失败的42.85%相比,几乎可以忽略了。 所以,**现代大容量硬盘组成的RAID5重建失败,并非是两个硬盘同时坏导致(不过从另一个角度来说,可以认为一个硬盘坏的时候,另外一个硬盘已经存在隐患,全盘读取会导致隐患暴露)。因此不要买同一批次硬盘组RAID,保留一个热备盘更安全这两个观点,起码在大容量硬盘流行的现在,已经是过时的观点了。**事实上,如果RAID卡或者驱动支持RAID 6,与其留一个热备盘,不如直接把RAID 5升级为RAID 6。 最后需要补充的是,**发生URE导致重建失败,并非意味着全部数据丢失——这是唯一值得安慰的地方**。数据基本上都还在可以恢复的,只是根据不同的RAID实现方案,可能需要不同的恢复方案:如果RAID卡/驱动允许,可以继续以降级模式运行,那么直接把所有数据复制到另外一个阵列就好;如果RAID卡遭遇URE后,强制某个硬盘离线并且不能重新上线,就需要找专业的数据恢复了。 不过因为URE的存在,这两种方案都可能会丢失一个或多个文件。严重的话,丢失文件系统结构的元数据(Metadata),会导致文件系统崩溃,只能通过数据恢复软件对整个阵列进行全盘扫描来恢复,这样恢复的成功率就很低了。好在通常元数据很小,发生这种情况的概率也很低。反过来,运气最好就是URE发生在未使用的空白区域上,则对数据没有任何影响。 另外,不管哪一种恢复方案,**由于需要另外一个同等容量的阵列来存放恢复出来的数据,对于家庭用户来说,通常都是非常麻烦——或者成本高昂的事情**。所以我在多个家用NAS主题下的回答,都明确反对家用NAS使用RAID 5。作为RAID 5的替代方案,答主建议如下: 1. 经济条件允许的,采购支持RAID 6的RAID卡,多牺牲一块硬盘的容量组建RAID 6。 2. DIY NAS的,使用支持ZFS的操作系统,多牺牲一块硬盘容量组RAID Z2。 3. 使用成品NAS的,牺牲一块硬盘容量组RAID 10(四盘位)或者RAID 6(5盘位及以上) 4. 玩不转Linux/BSD/Solaris的,又不需要阵列的持续性能的,用SnapRAID+计划任务。想安全的话,多牺牲一块硬盘组双校验盘的SnapRAID,等效RAID 6;经济原因或者机箱位置不够的,组单校验盘的SnapRAID也可以,因为SnapRAID是基于文件生成校验数据,即使碰到URE也只会丢失单个文件。 **最后的最后:** **RAID不是备份,重要数据,请做好备份。** **RAID不是备份,重要数据,请做好备份。** **RAID不是备份,重要数据,请做好备份。** **备份到移动硬盘,或者加密同步到网盘都是更安全的方案。** ------ [1] [DBA亲,你们的RAID5阵列有保障吗?-史振宁的技术博客-51CTO博客](http%3A//blog.51cto.com/magic3/1361554) [2] [Failure Trends in a Large Disk Drive Population - Research - GooglePDF](https://link.zhihu.com/?target=https%3A//research.google.com/archive/disk_failures.pdf) [3] [SCSI和SATA的稳定性](https://link.zhihu.com/?target=https%3A//lenciel.com/docs/scsi-sata-reliability/) [4] [Are Fibre Channel and SCSI Drives More Reliable?](https://link.zhihu.com/?target=https%3A//permabit.wordpress.com/2008/08/20/are-fibre-channel-and-scsi-drives-more-reliable/) [5] [Seagate 中国](https://link.zhihu.com/?target=https%3A//www.seagate.com/tech-insights/advanced-format-4k-sector-hard-drives-master-ti/) Loading... <div class="tip share">请注意,本文编写于 2284 天前,最后修改于 2284 天前,其中某些信息可能已经过时。</div> 转载自知乎 **一句话结论:现代大容量硬盘组成的RAID 5单盘故障后,重建失败的概率相当高,不可忽略;但数据本身还是基本安全的(会丢失部分文件),只是可能需要一个比较麻烦的恢复方案。** 楼上包括高赞回答在内一堆说两个硬盘同时坏的,要加一个热备盘的,都是没**仔细**看过问题里面的链接就回答的。在回答问题的现在,这个链接失效了,但网上还是有人转载过的,例如这篇[1]: > **DBA亲,你们的RAID5阵列有保障吗?** > marbury关注0人评论10546人阅读2014-02-21 10:30:24 > 该文章主要整理论坛内容。(论坛地址:[http://bbs.et8.net/bbs/showthread.php?t=1026112)](https://link.zhihu.com/?target=http%3A//bbs.et8.net/bbs/showthread.php%3Ft%3D1026112%EF%BC%89) > > 很多人遇到过服务器RAID5挂掉,往往掉一个盘后,第二个盘也立刻挂掉。 > > 引用:RAID 5也是以数据的校验位来保证数据的安全,但它不是以单独硬盘来存放数据的校验位,而是将数据段的校验位交互存放于各个硬盘上。这样,任何一个硬盘损坏,都可以根据其它硬盘上的校验位来重建损坏的数据。硬盘的利用率为n-1。如果挂掉两个盘,数据就玩完了。 > 理论上两个硬盘同时失效的概率是很低的,但为什么会这样呢? > 引用:从数学角度说,每个磁盘的平均无故障时间 (MTBF) 大约为 50 万至 150 万小时(也就是每 50~150 年发生一次硬盘损坏)。实际往往不能达到这种理想的情况,在大多数散热和机械条件下,都会造成硬盘正常工作的时间大幅减少。考虑到每个磁盘的寿命不同,阵列中的任何磁盘都可能出现问题,从统计学角度说,阵列中 N 个磁盘发生故障的机率比单个磁盘发生故障的机率要大 N 倍。结合上述因素,如果阵列中的磁盘数量合理,且这些磁盘的平均无故障时间 (MTBF) 较短,那么在磁盘阵列的预期使用寿命过程中,就很有可能发生磁盘故障(比方说每几个月或每隔几年就会发生一次故障)。 > 两块磁盘同时损坏的几率有多大呢(“同时”就是指一块磁盘尚未完全修复时另一块磁盘也坏掉了)?如果说 RAID 5 阵列的MTBF相当于MTBF^2,那么这种几率为每隔10^15个小时发生一次(也就是1万多年才出现一次),因此不管工作条件如何,发生这种情况的概率是极低的。从数学理论角度来说,是有这种概率,但在现实情况中我们并不用考虑这一问题。不过有时却是会发生两块磁盘同时损坏的情况,我们不能完全忽略这种可能性,实际两块磁盘同时损坏的原因与MTBF基本没有任何关系。 > 对这种情况来说,这里首先要引入一个一般人不常接触到的概念:BER 硬盘误码率,英文是BER(Bit Error Rate),是描述硬盘性能的一个非常重要的参数,是衡量硬盘出错可靠性的一个参数。这个参数代表你写入硬盘的数据,在读取时遇到不可修复的读错误的概率。从统计角度来说也比较少见,一般来说是指读取多少位后会出现一次读取错误。 > 随着硬盘容量增加,驱动器读取数据的误读率就会增加,而硬盘容量暴涨,误码率的比例一直保持相对增加。一个1TB的驱动器是需要更多读取整个驱动器,这是在RAID重建期间发生错误的概率会比300G 驱动器遇到错误的几率大。 > 那这个错误的几率到底有多大呢?或者说,我们写入多少GB数据,才会遇到1byte的读取错误呢?看这篇文章: > [http://lenciel.cn/docs/scsi-sata-reliability/](https://link.zhihu.com/?target=http%3A//lenciel.cn/docs/scsi-sata-reliability/) > > 对于不同类型的硬盘(以前企业级、服务器、数据中心级硬盘用SCSI/光纤,商用、民用级别是IDE;现在对应的则是SAS/SATA; > 他们的MRBF(平均无故障时间)是接近的,但是BER便宜的SATA硬盘要比昂贵的SCSI硬盘的误码率(BER)要高得多。 > 也就是说,出现某个sector无法读取的情况,SATA要比SCSI严重得多。具体区别在固件上:遇到读取不过去,或者写入不过去的坏道时,家用硬盘会花费1分钟以上的时间去尝试纠正错误,纠正不了就直接用备用扇区代替,这个时间超过阵列控制器能容忍的限度,所以遇到这种情况直接掉盘;企业级的磁盘会把这项工作放在后台进行,不需要停顿1分钟左右的时间,从而不影响阵列运行。在BER 硬盘误码率上没有任何区别。 > 按照文中的计算,一个1TB的硬盘,通常你无法读取所有sector的概率达到了56%,因此你用便宜的大容量SATA盘,在出现硬盘故障的情况下重建RAID的希望是:无法实现。 > 用1TB的SATA硬盘做RAID5的话,当你遇到一个硬盘失效的情况,几乎剩下的两个以上硬盘(RAID5最少组合是3个)铁定会遇到一个硬盘读取错误,从而重建失败。 > 所以,以前小硬盘做RAID5,基本很少遇到同时挂掉两个盘的情况;现在硬盘大了,出问题的概率也越来越大了。 > 对于跑RAID的用户,对整个硬盘进行读取的事情经常发生。即使系统足够和谐,知道不对你报告那些出现在你从不读取的文件中的坏道,但是也只是略过了报告这一步:它还是会找到所有的坏道,56%就来了。还有所谓的监控专用企业级SATA,其原理就是在固件上做手脚,让硬盘即使遇到写入的数据读取错误,也不管三七二十一直接跳过,不再重试读取(标准硬盘的读取方式是遇到某个扇区CRC错误自动重新再去读,直到读到正确的数据为止)。这对监控数据来说是理所当然的(大多数监控的硬盘都是在不停地写入,但是很少需要读取),除非遇到出现问题需要重现影像时。 > 现有的Raid5阵列的磁盘中有未检测到的错误的话,Hot Spare没办法解决。Hot Spare只能在某个磁盘下线的时候,及时的替换下线的盘进行Raid重建,如果其他磁盘有错误的话,重建还是会可能失败。 > 解决方法还是要在阵列健康状态下,进行定期或者其他方式的错误检查。一般的硬件阵列卡,也就是插在主板PCI/PCIX/PCIE/或者主板集成的RAID5,压根就没数据巡检(scrub)功能。企业级的数据存储,也只有到盘阵级别(比如IBM DS3000/4000/5000,DELL MD3000....etc)才有这类功能,但是你也看不到检查的结果,最多能在日志里看到某个硬盘CRC失败,然后跳红灯掉出来,阵列柜告警通知你换硬盘。你别想知道这个硬盘到底是彻底挂了呢,还是有读取错误,还是有坏道。。。总之两眼一抹黑。(ZFS上的RAIDZ有数据巡检(scrub)功能) > 总结遇到RAID5一次挂掉俩盘的概率 > 1、使用越大容量的硬盘做RAID5,遇到BER 扇区的概率越大;比如用100G硬盘做RAID5就比用1TB的安全; > 2、使用越多盘数的硬盘做RAID5,遇到BER 扇区的概率越大;比如用3个盘做的RAID5,比6个盘做的RAID5安全; > 3、使用越便宜的硬盘做RAID5,遇到BER 扇区的概率越大;比如用SCSI/FC/SAS盘比用IDE/SATA的RAID5安全; > 4、RAID5里面存放的数据越多,塞得越满,遇到BER 扇区的概率越大;比如存了100G数据的比存了1TB数据的RAID5安全;(REBUID时只读取存过数据的扇区,某些卡则不管三七二十一要读完整个盘) > RAID1/RAID10参与重建的只有一个盘,与raid5所有盘都需要参与重建相比,故障概率降低;RAID1 某一组磁盘故障,也不需要强制上线的操作,因为数据仍然存在,不需要组RAID也能读取,哪怕是换到其他没有raid卡的机器上数据仍能读出;而RAID5如果不能强制第二个掉下的硬盘上线,你一点东西都读不到。 > 对于DB来说:做raid 1+0 是最好不过啦!(备份时必不可少的;当RAID处理降级状态时,如重要数据容量不大,建议先做备份,当然这种备份应该是异机的,不可备份至当前已降级的RAID中。如果在REBUILD当中出现另外硬盘离线的情况导致RAID卷OFFLINE,切不可重建RAID,如确定后离线的硬盘,可通过强制上线恢复数据(有些控制器没有选项,就没办法了) > > > 本文出自 “技术成就梦想” 博客,请务必保留此出处[http://weipengfei.blog.51cto.com/1511707/1006565](https://link.zhihu.com/?target=http%3A//weipengfei.blog.51cto.com/1511707/1006565) 这篇文章有两个我认为不正确的地方: - 用硬盘厂家标称的MTBF来计算第二块硬盘发生故障概率是不适当的。如果参考谷歌的论文[2],5年内硬盘的最高年平均故障率为8.6%(下面估算中用稍高一点的10%进行估算)。按照这篇文章所说的1TB硬盘,假设平均写入速度为100MB/s计算,重建RAID 5需要写满一个硬盘,大概需要 ![[公式]](https://www.zhihu.com/equation?tex=1e12+%5Cdiv+100e6+%5Cdiv+3600+%3D+2.78) 小时。如果以8盘RAID5计算的话,单个硬盘故障后还有7个硬盘,在2.78小时内单个硬盘发生故障的概率可以用 ![[公式]](https://www.zhihu.com/equation?tex=10+%5C%25+%5Cdiv+365+%5Cdiv+24+%5Ctimes+2.78+%3D+3.17e-5) 计算。7个硬盘在2.78小时一个或一个以上硬盘出现故障的概率可以用binomial distribution(二项分布)的概率质量公式计算: ![[公式]](https://www.zhihu.com/equation?tex=Pr%5Cleft%28+X+%5Cgeq+1+%5Cright%29+%3D+%5Csum_%7Bi%3D1%7D%5E%7B7%7D%7B+%5Cbinom%7B7%7D%7Bi%7D+p%5E%7B7%7D+%5Cleft%281-p%5Cright%29%5E%7B7-i%7D%7D) ,其中P=3.17e-5。这里的这个公式可以简化为 ![[公式]](https://www.zhihu.com/equation?tex=1-Pr%280%29%3D1-%5Cbinom%7B7%7D%7B0%7Dp%5E%7B0%7D%281-p%29%7B7%7D) 后用Excel计算,计算函数为=1-BINOMDIST(0,7,3.17e-5,TRUE),计算结果为2.22e-4,也就是0.022%。如果考虑到RAID 5重建过程中还有其它IO应用,或者RAID卡重建性能较差,导致重建速度降低,假设平均写入速度只有20MB/s,则重建时间约为14小时,重建过程中出现第二个硬盘故障的概率为0.11%。也就是大概每1000次重建可能出现1次第二个硬盘故障。也就是说,在一个部署了上万硬盘并且均组成RAID5阵列的数据中心中,几乎每年都会发生一例,并非是文中所说的“在现实情况中我们并不用考虑这一问题”。2019年的今天,单个硬盘最大容量已经达到14TB,假设重建速度保持在20MB/s,这个概率会进一步提升到1.54%;即使重建速度提升到50MB/s,这个概率还有0.62%,超过1/200。**不过即使这样,和因为URE导致的重建失败的概率(见后文)相比,这也是一个相当低的概率。**   - “一个1TB的硬盘,通常你无法读取所有sector的概率达到了56%”这句话是不正确的,要搞清楚这个概率的出处,需要去看文中链接的文章。不过,这篇文章中引用的链接地址无法访问的,估计是博主换了域名,通过搜索找到新域名链接[3],但[3]依然没有给出这个数据是如何计算出来的。只提到: > 最近看到**[一篇文章](https://link.zhihu.com/?target=http%3A//permabit.wordpress.com/2008/08/20/are-fibre-channel-and-scsi-drives-more-reliable/)**讨论SATA和SCSI硬盘的可靠性问题。这篇文章的结论是:两种硬盘的故障率(**[MTBF](https://link.zhihu.com/?target=http%3A//en.wikipedia.org/wiki/MTBF)**)是极其接近的,只不过便宜的SATA硬盘要比昂贵的SCSI硬盘的**误码率([BER](https://link.zhihu.com/?target=http%3A//en.wikipedia.org/wiki/Bit_error_ratio))要高得多。**也就是说,出现某个sector无法读取的情况,SATA要比SCSI严重得多。按照他的计算,一个1TB的硬盘,通常你无法读取所有sector的概率达到了56%,因此你在出现硬盘故障的情况下重建RAID的希望是:**无法实现**。 点击上面的“这篇文章”的链接[4],原文部分摘录如下: > Where there is a difference between models, though, is with our old friend, the [bit error rate](https://link.zhihu.com/?target=https%3A//permabit.wordpress.com/2008/08/15/multiple-drive-failures-raid-6-vs-rain-ec/). The bit error rate is the rate at which a block just can’t be read from the disk, due to not being able to recover data from the [PRML](https://link.zhihu.com/?target=http%3A//en.wikipedia.org/wiki/PRML) and ECC codes on the platter. The whole drive doesn’t fail, but you can’t read that block. In a RAID system, this triggers reconstruction of that block from the remaining drives. > > As I describe in the video [“The Trouble with RAID”](https://link.zhihu.com/?target=http%3A//www.permabit.com/videos/raid45/permabit-raid45.asp), this bit error rate is the biggest problem with RAID technology today. In the event of a drive failure in a RAID 4 or RAID 5 set, every remaining drive must be read perfectly from start to finish or else data will be lost. With a 7+1 set of terabyte drives, this means 7 TB must be read. A bit error rate of 1 in 10^14 means that there’s a **44%** chance that can’t be done. 摘录部分翻译如下: 然而,不同型号(译注:原文指消费级硬盘及SCSI/光纤通道硬盘)之间存在的差异是我们所熟知的误码率。误码率是指由于无法通过PRML和ECC从盘片上的恢复数据而无法从磁盘读取某个扇区数据的概率。硬盘整体来说并未发生故障,但用户无法读取该扇区的数据。在RAID系统中,这会触发用其它硬盘上的数据对该扇区数据恢复的重建过程。 正如我在视频中描述的“RAID的麻烦”一样,这种误码率是当今RAID技术最大的问题。如果RAID 4或RAID 5中的驱动器发生故障,则剩余的每个硬盘都必须从头到尾“完美”的读取一遍,否则将会导致数据丢失。使用7+1个1 TB容量硬盘,这意味着必须读取7 TB。1/10^14的误码率为意味着有44%的概率无法做到(“完美”读取7TB数据)。 译注: - PRML:Partial-response maximum-likelihood,部分响应最大似然,一种提高磁头读取磁盘后产生的微弱模拟信号数字化准确度的技术。 - ECC:Error Correct Code,纠错码,一种通过传输/保存冗余编码的数据位,在原始数据发生传输错误时可以检测到错误并恢复出正确数据的技术。 [4]所提到的bit error rate,现在各家硬盘厂商的Datasheet中通常叫Non-recoverable Read Error rate,网上包括维基通常用Unrecoverable Read Error rate(URE,本文均使用此缩写),也就是[1]所提到的“**写入硬盘的数据,在读取时遇到不可修复的读错误的概率**”。 稍微解释一下,这个读错误产生的原因可能在于: - 数据写入硬盘时,数字信号转换为盘片上的模拟磁场信号过程中发生错误; - 数据存放过程中,因为外界的电磁干扰/宇宙射线/写入周围单元时磁头位置偏离导致的磁单元中部分磁性材料极性翻转; - 读取数据时,磁场信号转换为数字信号过程中发生错误; 在硬盘内部,这种错误其实是经常发生的,但一般来说每个扇区可能也就1~3 bit的数据发生这种错误。因此机械硬盘每个扇区后面有若干位ECC纠错码(早期的512B扇区硬盘是每扇区50Byte,现在的4K扇区硬盘是每扇区100Byte[5]),可以用于纠正此类错误。然而ECC不是万能的,如果读取某个扇区的数据时发生错误的位过多,ECC也无能为力,这个时候就发生“不可恢复的读取错误(也就是前面定义中的Unrecoverable Read Error)”了。按照硬盘厂家提供的参数,发生这种情况的概率——也就是URE,消费级硬盘一般是1e-14,企业级硬盘发生URE的概率一般是1e-15。 [4]并没有给出具体的计算根据URE计算RAID5重建成功概率的公式,这里稍微补充一下。如果某款硬盘的URE是1e-14/bit(这个可以从各家硬盘厂商的DataSheet中查到),并不代表每读取1e+14 bit就一定出现一次URE。同样可以用二项分布公式计算,读取1e14bit发生URE的概率: - 0次: ![[公式]](https://www.zhihu.com/equation?tex=Pr%5Cleft%28+X+%3D+0+%5Cright%29+%3D+%5Cbinom%7B1e14%7D%7B0%7D+%5Cleft%28+1e-14+%5Cright%29%5E%7B0%7D+%5Cleft%281+-+1e-14%5Cright%29%5E%7B1e14%7D%3D36.79+%5C%25) - 1次: ![[公式]](https://www.zhihu.com/equation?tex=Pr%5Cleft%28+X+%3D+1+%5Cright%29+%3D+%5Cbinom%7B1e14%7D%7B1%7D+%5Cleft%28+1e-14+%5Cright%29%5E%7B1%7D+%5Cleft%281+-+1e-14%5Cright%29%5E%7B1e14-1%7D%3D29.05+%5C%25) - 2次: ![[公式]](https://www.zhihu.com/equation?tex=Pr%5Cleft%28+X+%3D+2+%5Cright%29+%3D+%5Cbinom%7B1e14%7D%7B2%7D+%5Cleft%28+1e-14+%5Cright%29%5E%7B2%7D+%5Cleft%281+-+1e-14%5Cright%29%5E%7B1e14-2%7D%3D22.94+%5C%25) - …… 不过1e14次试验,1e-14的概率这样的数字,Excel是算不了了,可以用Python的scipy库计算: ```python >>> from scipy.stats import binom >>> binom.pmf(0, 1e14, 1e-14) 0.36787944117144045 >>> binom.pmf(1, 1e14, 1e-14) 0.2904884966524753 >>> binom.pmf(2, 1e14, 1e-14) 0.22937831594696387 >>> binom.pmf(3, 1e14, 1e-14) 0.04041420666321343 >>> binom.pmf(4, 1e14, 1e-14) ``` 我们只关心不发生URE的概率,也就是0次。因此二项分布的概率质量函数可以这样简化: ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Bequation%7D+%5Cbegin%7Baligned%7D+Pr%28X%3D0%29%26%3D%5Cbinom%7Bn%7D%7Bk%3D0%7Dp%5E%7Bk%7D%281-p%29%7Bn-k%7D%5C%5C+%26%3D%5Cfrac%7Bn%21%7D%7B0%21%28n-0%29%21%7Dp%5E%7B0%7D%281-p%29%5E%7Bn%7D%5C%5C+%26%3D%281-p%29%5E%7Bn%7D+%5Cend%7Baligned%7D+%5Cend%7Bequation%7D+) 而4个1TB硬盘组成的RAID 5,单盘故障后的重建过程需要读取的数据量为1e12 Byte×8 bit/Byte×(4-1)=24Tbit,而读取24Tbit过程中没有发生URE的概率则是(1-1e14)^24e12=78.68%。用Excel可以很轻松计算出重建RAID5过程中,不同误码率,不同容量的硬盘,组成4/8盘RAID 5的重建成功/失败概率,见下表(PS:Excel用简化公式计算和用scipy直接计算的结果会稍有出入,但可以忽略)。   表中8个URE为1e-14建立的RAID 5重建成功概率为57.15%,和[4]所说的44%失败比较接近了。所以前面[1]所说的56%,是8个1TB硬盘组成的RAID5,重建过程中因为发生URE导致重建失败的概率。而单个1TB硬盘完全读取,发生URE的概率应该是7.68%。 进一步观察估算结果,其实单个硬盘全盘读取,8TB容量出现URE概率已经接近50%了。也所以现在8TB以上(含8TB)的硬盘,即使是消费级的,也都是1e-15的URE——起码希捷的最新产品线是这样。倒是企业级的Exos 5E8只有一款8TB型号,反倒标称的URE参数是1e-14。 从上表可见4个URE为1e-14的1TB硬盘组成的RAID 5重建失败的概率为21.32%,其实已经相当高了;8个URE为1e-14的硬盘组RAID5的话,1~2TB还可以拼一下脸,3~4TB那叫玩命,6~8TB就是碟中谍了。 需要说明的是,通常RAID 5是在硬件层面(有独立主控芯片的RAID卡,常说的硬RAID)或者块设备驱动层面(主板或操作系统,软RAID)实现的,与文件系统独立。因此RAID控制芯片或者驱动是无法知道RAID上某一段数据,到底是存有数据的文件,还是某个已经被删除的文件;也不知道某一段全0的数据,到底是未使用空间还是某个预分配磁盘空间但未使用的数据库文件。因此即使一个1TB*8,可用空间7TB的RAID 5,假设用户仅仅存放了50GB数据,重建的时候还是必须把7TB的数据全部读取一遍的。对于这种情况,RAID 5EE、RAID 2.0,以及由文件系统本身实现类似RAID 5的RAID Z1(ZFS文件系统),则是可以仅重建已经使用的50GB数据。 对比前面分析,重建过程中第二块硬盘出现故障导致重建失败的概率,8个1TB硬盘低速重建也不过0.11%,但因为URE导致重建失败的概率则是高达42.85%。题目和其它部分答案所提到的热备盘,其意义在于RAID卡/驱动发现单个硬盘故障的时候,可以马上进入重建过程。假设没有热备盘,需要24小时后才能开始重建,按照前面的计算,8个1TB硬盘组成的RAID 5的重建时间从14小时延长到38小时,这个期间第二块硬盘发生故障的概率约为0.30%,和发生URE导致重建失败的42.85%相比,几乎可以忽略了。 所以,**现代大容量硬盘组成的RAID5重建失败,并非是两个硬盘同时坏导致(不过从另一个角度来说,可以认为一个硬盘坏的时候,另外一个硬盘已经存在隐患,全盘读取会导致隐患暴露)。因此不要买同一批次硬盘组RAID,保留一个热备盘更安全这两个观点,起码在大容量硬盘流行的现在,已经是过时的观点了。**事实上,如果RAID卡或者驱动支持RAID 6,与其留一个热备盘,不如直接把RAID 5升级为RAID 6。 最后需要补充的是,**发生URE导致重建失败,并非意味着全部数据丢失——这是唯一值得安慰的地方**。数据基本上都还在可以恢复的,只是根据不同的RAID实现方案,可能需要不同的恢复方案:如果RAID卡/驱动允许,可以继续以降级模式运行,那么直接把所有数据复制到另外一个阵列就好;如果RAID卡遭遇URE后,强制某个硬盘离线并且不能重新上线,就需要找专业的数据恢复了。 不过因为URE的存在,这两种方案都可能会丢失一个或多个文件。严重的话,丢失文件系统结构的元数据(Metadata),会导致文件系统崩溃,只能通过数据恢复软件对整个阵列进行全盘扫描来恢复,这样恢复的成功率就很低了。好在通常元数据很小,发生这种情况的概率也很低。反过来,运气最好就是URE发生在未使用的空白区域上,则对数据没有任何影响。 另外,不管哪一种恢复方案,**由于需要另外一个同等容量的阵列来存放恢复出来的数据,对于家庭用户来说,通常都是非常麻烦——或者成本高昂的事情**。所以我在多个家用NAS主题下的回答,都明确反对家用NAS使用RAID 5。作为RAID 5的替代方案,答主建议如下: 1. 经济条件允许的,采购支持RAID 6的RAID卡,多牺牲一块硬盘的容量组建RAID 6。 2. DIY NAS的,使用支持ZFS的操作系统,多牺牲一块硬盘容量组RAID Z2。 3. 使用成品NAS的,牺牲一块硬盘容量组RAID 10(四盘位)或者RAID 6(5盘位及以上) 4. 玩不转Linux/BSD/Solaris的,又不需要阵列的持续性能的,用SnapRAID+计划任务。想安全的话,多牺牲一块硬盘组双校验盘的SnapRAID,等效RAID 6;经济原因或者机箱位置不够的,组单校验盘的SnapRAID也可以,因为SnapRAID是基于文件生成校验数据,即使碰到URE也只会丢失单个文件。 **最后的最后:** **RAID不是备份,重要数据,请做好备份。** **RAID不是备份,重要数据,请做好备份。** **RAID不是备份,重要数据,请做好备份。** **备份到移动硬盘,或者加密同步到网盘都是更安全的方案。** ------ [1] [DBA亲,你们的RAID5阵列有保障吗?-史振宁的技术博客-51CTO博客](http%3A//blog.51cto.com/magic3/1361554) [2] [Failure Trends in a Large Disk Drive Population - Research - GooglePDF](https://link.zhihu.com/?target=https%3A//research.google.com/archive/disk_failures.pdf) [3] [SCSI和SATA的稳定性](https://link.zhihu.com/?target=https%3A//lenciel.com/docs/scsi-sata-reliability/) [4] [Are Fibre Channel and SCSI Drives More Reliable?](https://link.zhihu.com/?target=https%3A//permabit.wordpress.com/2008/08/20/are-fibre-channel-and-scsi-drives-more-reliable/) [5] [Seagate 中国](https://link.zhihu.com/?target=https%3A//www.seagate.com/tech-insights/advanced-format-4k-sector-hard-drives-master-ti/) 最后修改:2020 年 03 月 02 日 © 允许规范转载 打赏 赞赏作者 赞 2 如果觉得我的文章对你有用,请随意赞赏